



Mysql has many open-source backup tools out there, some of which are mysqldump, mydumper for logical backups and xtrabackup for hot physical backups. They do their jobs very well and they are feature-rich. However, it is a common thing to back up the data with these tools but forget about the binary logs that are essential for point-in-time recovery. No matter what type of backup you have, you must have binary logs starting from a full backup, till the point in time you want to go back.
mysqlbinlog --raw --read-from-remote-server --stop-never
mysqlbinlog utility has already a great feature to synchronize binary logs in real-time to another location. The above command connects to your MySQL instance, acting as a slave server (--read-from-remote-server), requesting raw binary logs without any modification ( --raw) until forever (* --stop-never*). This feature alone has some pros and cons.
Pros
No need to worry about MySQL configuration changes, binlog path etc., as it will understand them automatically
This way original binary log files can be limited to a few days to avoid bloating the disk, but the copies can be kept longer in a different disk.
Cons
Not much flexibility, it just copies the new content to the current directory
No built-in compression or encryption option
Recently, I’ve been setting up a 2-node MySQL master-slave setup business app. Data size is not expected to be very big, therefore I just configured xtrabackup to take full backups for each day. However, since the business is mission-critical and the data is highly relational, a few missing records would become a nightmare. So, I wanted to make sure that we have a backup of everything at any time so wrote a shell script to automate the backup of binary logs with a few useful options. The following command does just a few things:
./syncbinlog.sh --backup-dir=/mnt/backup --compress --rotate=30
Run mysqlbinlog, auto restart on failure and continue from the last backed-up binary log file. Use /mnt/backup for the destination directory.
Check backup files that are already closed and compress them using pigz (parallel gzip).
Delete old backup files depending on a given rotation policy such as keeping the last 30 days of backups.
Now, I have backup automation enough for a small-scale project. The script is located here with more details: mysql-binlog-backup
Recovery
So, what happens if something goes wrong like a bad query dropping an important table or deleting undesired records? There are a few possibilities.
If the slave server is configured with a delayed replication, it may not be too late to promote it as master and skip problematic queries.
Otherwise, a point-in-time recovery is necessary.
For the 2nd case, the latest full backup before the problem must be restored using relevant tools. Doing this is trivial with xtrabackup. Since it dumps the final binary log file and position of the backup, it can be used with mysqlbinlog to create a logical dump starting from the backup position to the point before trouble. Example contents of xtrabackup_binlog_info:
mysql-bin.000111 1124
You must also find the problematic query position in binary logs, by first guessing the correct binary log file which contains it. If you know the time of execution approximately, you can find it by checking the timestamps of binary log files with ls -la and dumping its content to search for the query. The following command creates a readable SQL file.
mysqlbinlog --base64-output=DECODE-ROWS --verbose mysql-bin.000113 > debug.sql
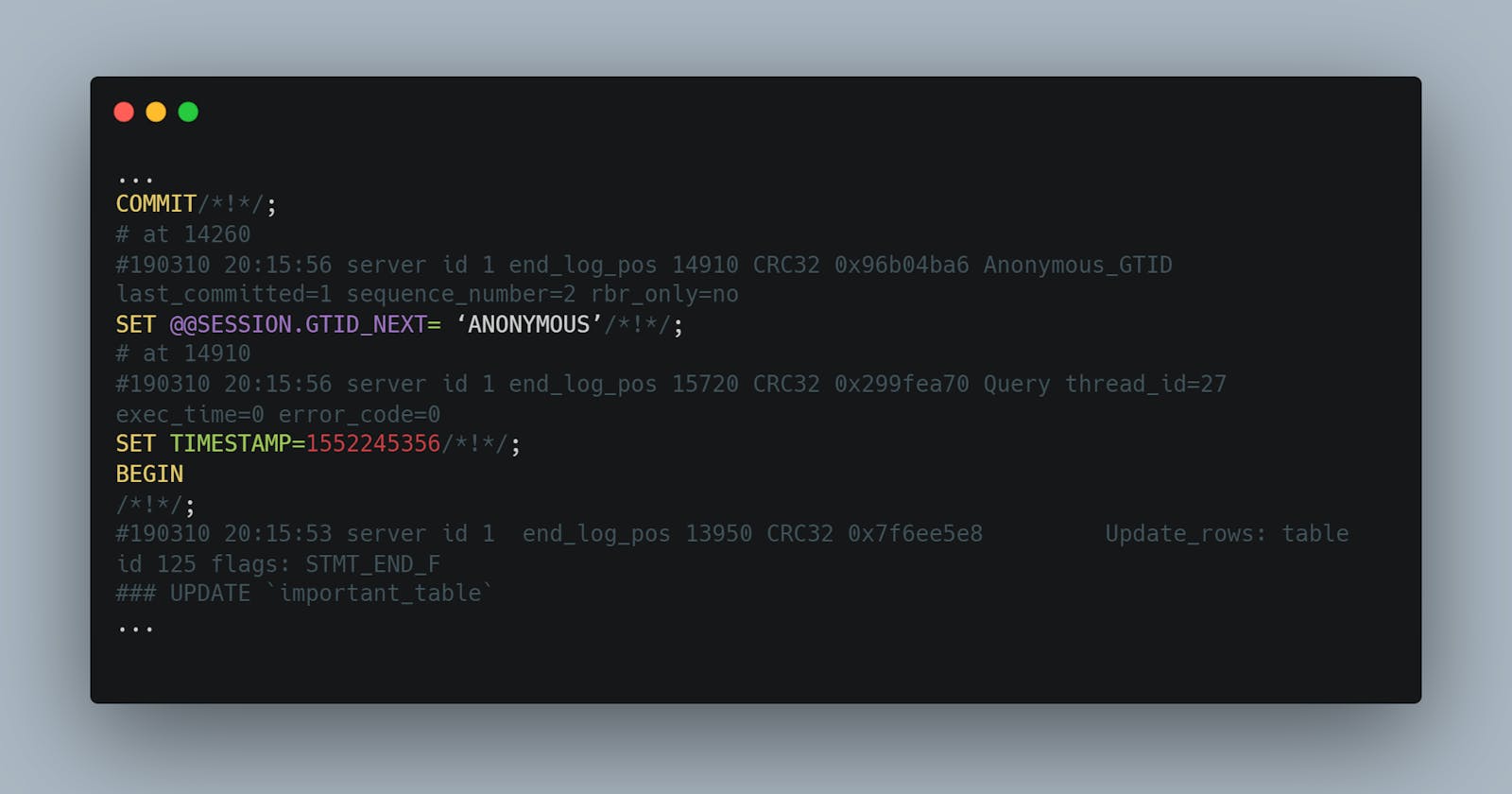
One must be careful while searching for the correct position. There are transaction logs starting with BEGIN until COMMIT. Picking a position between will result in an error. Otherwise, a wrong position will repeat the whole restoration process. Here is an example piece of the binary log, where the correct position would be 15720, just before the problematic UPDATE query.
...
COMMIT/*!*/;
# at 14260
#190310 20:15:56 server id 1 end_log_pos 14910 CRC32 0x96b04ba6 Anonymous_GTID last_committed=1 sequence_number=2 rbr_only=no
SET @@SESSION.GTID_NEXT= ‘ANONYMOUS’/*!*/;
# at 14910
#190310 20:15:56 server id 1 end_log_pos 15720 CRC32 0x299fea70 Query thread_id=27 exec_time=0 error_code=0
SET TIMESTAMP=1552245356/*!*/;
BEGIN
/*!*/;
#190310 20:15:53 server id 1 end_log_pos 13950 CRC32 0x7f6ee5e8 Update_rows: table id 125 flags: STMT_END_F
### UPDATE `important_table`
...
Now, the relevant logs must be re-executed until that position. (Considering full backup is already restored before)
Notes
There are more advanced ways to do PITR(point-in-time-recovery), such as restoring the backup to another instance in vm/container, copying binary log files there, and letting myself sql_thread apply them in parallel. This is necessary in busy databases since mysqlbinlog is single-threaded and slow. However, this topic is not part of this article.
Some useful articles about point-in-time-recovery: